Abstract
This paper presents an approach that reconstructs a hand-held object from a monocular video. In contrast to many recent methods that directly predict object geometry by a trained network, the proposed approach does not require any learned prior about the object and is able to recover more accurate and detailed object geometry. The key idea is that the hand motion naturally provides multiple views of the object and the motion can be reliably estimated by a hand pose tracker. Then, the object geometry can be recovered by solving a multi-view reconstruction problem. We devise an implicit neural representation-based method to solve the reconstruction problem and address the issues of imprecise hand pose estimation, relative hand-object motion, and insufficient geometry optimization for small objects. We also provide a newly collected dataset with 3D ground truth to validate the proposed approach.
Method
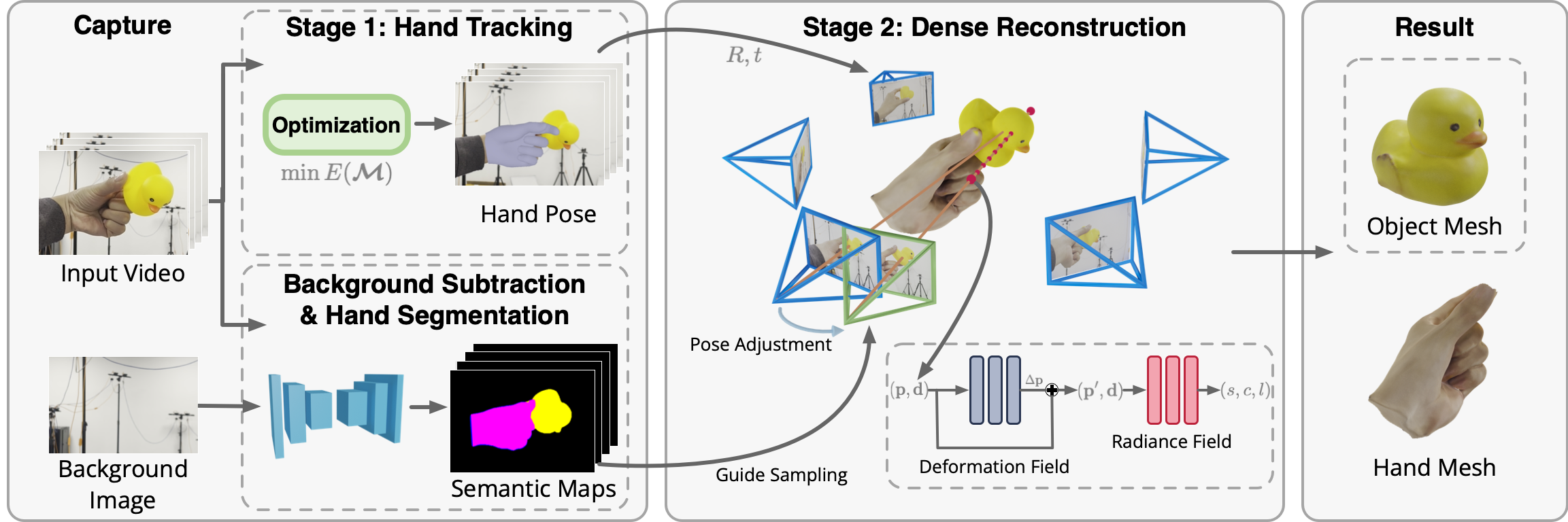
The pipeline of our approach, which consists of two stages. Hand tracking: by minimizing the reprojection error of hand keypoints detected by a learned detector, the 3D hand pose and the camera motion relative to it are recovered. Dense reconstruction: an implicit neural representation-based method is employed to reconstruct the SDF and color fields of the hand and object. Three additional modules are proposed: the pose adjustment to compensate for imprecise hand pose tracking, the deformation field to model the relative motion between the hand and object, and the semantics-guided sampling to improve object reconstruction quality.
Video
Comparison